机器学习的一般步骤是:训练样本 - 特征抽取 - 学习函数 - 预测。其中,为了使模型型获得更多训练,预测和学习函数是在不断循环的。
机器学习的问题可以分为两种类型:分类问题 和预测问题。分类模型是将数据最终归于某一个类型,而预测模型的结果更多的是一个具体数值。这里先讲一讲机器学习中经典的回归算法。
线性回归
我们用一个例子来展现线性回归的建模过程。下表是一个银行判断用户贷款额度的数据集,其中,银行给用户的贷款额度取决于两个因素:工资和年龄,这两个因素就是这个数据集的_特征_。
| 工资( |
年龄( |
额度( |
|---|---|---|
| 4000 | 25 | 20000 |
| 8000 | 30 | 70000 |
| 5000 | 28 | 35000 |
| 7500 | 33 | 50000 |
| 12000 | 40 | 85000 |
建立模型
根据上表,给每个特征 一个参数
,构成根据特征预测出的额度
:
但是预测的额度与真实值之间可能会有一定的误差,于是真实的额度可以表示为
其中误差 是_独立_(样本直接无关联)且_具有相同分布_(大部分误差在一个范围中)的,通常被认为服从均值为 0、方差为
的 高斯分布
-
假设误差分布为
(即
其中
用公式
替换误差
,得到
这里
,即
似然函数和目标函数
我们希望每个预测值都尽量接近真实值,所以构造了 似然函数:
这里_累乘所有样本的概率值,目标是使 尽可能大_。(因为如果每个训练样本的预测值都接近真实值,即误差很小,那么每个概率
都会接近 1,于是它们的累乘也会接近 1。)
为了方便计算,我们将 中的乘法转换成加法运算,即对
做对数运算,得到 对数似然函数:
因为 的前半部分
为常数,不会被
改变,所以要使
尽可能大,它的后半部分
需要尽可能小(这里后半部分一定大于 0,所以需要使其尽可能接近 0)。最后得到 目标函数
(留下 方便求导)
求导
我们的目标是找到_使 尽可能小的
值_。对一个函数取极值,可以对其进行求导。
我们用矩阵形式表示 中
:
为了求 的极值,需要对
求偏导
令 ,即
,则
Logistic 回归
逻辑回归是一个分类算法。
S 函数(Sigmoid 函数)
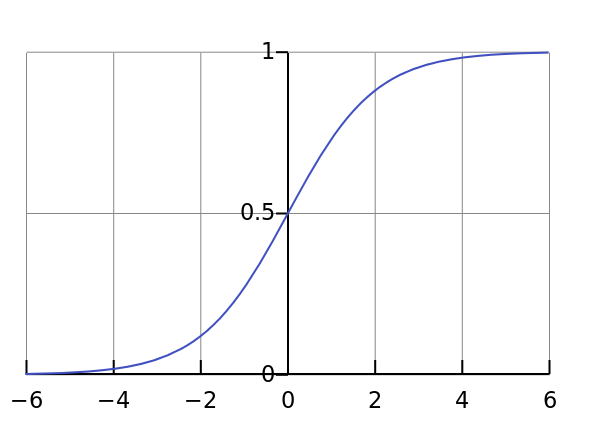
-
函数表达式为
-
取值范围
建模
由 S 函数可以看出,逻辑回归就是把模型的计算结果映射在 S 函数上,使最终结果在 区间上。我们可以设置 0.5 为分界,结果小于 0.5 的数据归于一类,大于 0.5 的归于一类。
令
这里符号含义同上,即 是预测值。
之后建立目标函数的步骤与线性回归一致。
梯度下降
参数 是无法一步优化到位的,我们需要一步一步使
向函数的“坡下”走,这个向下走的“方向”就是函数在当前位置对
的偏导数。
假设数据集只有一个特征,则预测值为
目标函数为
(这里如果不乘 ,意味着训练样本越多
越大)
对 和
分别求偏导
使每个参数沿梯度下降方向前进 步
这里 称为 学习率(或步长),步长过大可能略过最优点,步长太小迭代速度太慢。
当参数经过迭代后改变很小时,迭代结束,我们认为当前 是(或近似)最优解。